
It is a while since I published my last post here. There are several reasons that I don't write anything, for example, SAP does not publish new features for Analysis for Office or my current project has no special cool new things I can talk about because it is mostly just maintenance and nothing hip. So it was very quiet here, and this is what I want to change. If you follow me on Twitter, you could have seen this post.
The year is almost over, and I haven't written a lot of post on my blog this year. I have to do it a lot more next year. Some #DataWarehouseCloud, #Python and also #ABAP topics are on my list.
— Tobias Meyer (@reyemsaibot) December 17, 2021
So I will write some posts about Python, Data Warehouse Cloud, and some ABAP topics in the near future. This post starts with Python and how to analyze the Apple Health data.
You can export the health data from your iPhone and receive a ZIP file that contains an XML file. How you can do this can be found via Google. It is uncomplicated. In my case, my XML file was around 1 GB big, and it contains about 3 million entries until May 2021. So I could not analyze it with Microsoft Excel or Notepad++, and I need only some information out of it, so I tried Python. I work with Python just more than one year, so please be kind if it is not perfectly written code.
First we have to load the XML data.
from lxml import etree tree = etree.parse(r'path_to_xml\Export.xml') root = tree.getroot() # consider only records no workouts records = tree.xpath("//Record")
With this code snippet, we load the XML file. We are only interested in the record data, so we read only this and not the workout data. If you are interested in your workout data, I will create another example. The XML path is here //Workouts. The next step is to get the data and put it into a data frame.
import pandas as pd # fields we want to get DATETIME_KEYS = ["startDate", "endDate"] NUMERIC_KEYS = ["value"] OTHER_KEYS = ["type", "sourceName", "unit"] ALL_KEYS = DATETIME_KEYS + NUMERIC_KEYS + OTHER_KEYS # Get all records where as source the apple watch is df = pd.DataFrame([{key: r.get(key) for key in ALL_KEYS} for r in records if 'Apple' in r.attrib['sourceName']])
Now we have all data in the data frame and can display it with df.tail()

In this example I want to focus on my steps, so we filter for the type HKQuantityTypeIdentifierStepCount.
df_steps = df.query('type == "HKQuantityTypeIdentifierStepCount"')
Now we have in the new data frame df_steps only the step data. We can now save the data frame to a CSV file, and we can process it further.
df_steps.to_csv("data_health/steps.csv", index=False)
The XML file with almost 1 GB size has become a CSV file with 50 MB. Now you can use Microsoft Excel to open it or process the data further with Python. I found a blog post that also analyzes Apple Health data. I use this blog post to analyze my steps. First, we have to import some libraries.
from datetime import date, datetime, timedelta as td import pytz import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
After that, I use the conversion for the time column to get time fields I can use for aggregation. In my case, I use the time zone Berlin.
convert_tz = lambda x: x.to_pydatetime().replace(tzinfo=pytz.utc).astimezone(pytz.timezone('Europe/Berlin')) get_year = lambda x: convert_tz(x).year get_month = lambda x: '{}-{:02}'.format(convert_tz(x).year, convert_tz(x).month) #inefficient get_date = lambda x: '{}-{:02}-{:02}'.format(convert_tz(x).year, convert_tz(x).month, convert_tz(x).day) #inefficient get_day = lambda x: convert_tz(x).day get_hour = lambda x: convert_tz(x).hour get_minute = lambda x: convert_tz(x).minute get_day_of_week = lambda x: convert_tz(x).weekday()
Now we add several columns like the year, month, date, hour, day of the week.
df_steps['startDate'] = pd.to_datetime(df_steps['startDate']) df_steps['year'] = df_steps['startDate'].map(get_year) df_steps['month'] = df_steps['startDate'].map(get_month) df_steps['date'] = df_steps['startDate'].map(get_date) df_steps['day'] = df_steps['startDate'].map(get_day) df_steps['hour'] = df_steps['startDate'].map(get_hour) df_steps['dow'] = df_steps['startDate'].map(get_day_of_week)
With df_steps.tail() we can look into the data frame and it looks like this:
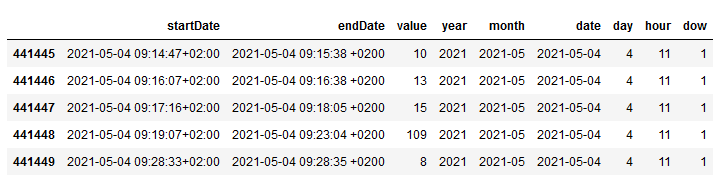
So we can aggregate the steps by date to summarize all records of one day into one single record.
steps_by_date = steps.groupby(['date'])['value'].sum().reset_index(name='Steps')
We can use the new data frame to visualize the result in a line chart diagram. I use the mean value of 30 days to show me an overview. You can change the value to your desire.
steps_by_date['RollingMeanSteps'] = steps_by_date.Steps.rolling(window=30, center=True).mean() steps_by_date.plot(x='date', y='RollingMeanSteps', title= 'Daily step counts rolling mean over 30 days', figsize=[10, 6])
This is how it looks:
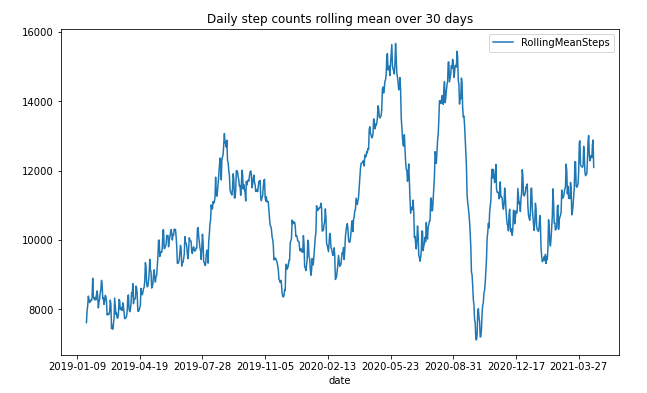
As you can see, I have a drop around the COVID-19 start, and as the lockdown in Germany started, I have an increase because we have done a lot of walking with the family. I think this is impressive to see and to analyze for further analysis. So the next step is to get an overview of the weekdays. Therefore, we have to add the weekday to our data frame and visualize it in a diagram.
steps_by_date['date'] = pd.to_datetime(steps_by_date['date']) steps_by_date['dow'] = steps_by_date['date'].dt.weekday data = steps_by_date.groupby(['dow'])['Steps'].mean() fig, ax = plt.subplots(figsize=[10, 6]) ax = data.plot(kind='bar', x='day_of_week') n_groups = len(data) index = np.arange(n_groups) opacity = 0.75 ax.yaxis.grid(True) plt.suptitle('Average Steps by Day of the Week', fontsize=16) dow_labels = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'] plt.xticks(index, dow_labels, rotation=45) plt.xlabel('Day of Week', fontsize=12, color='red')
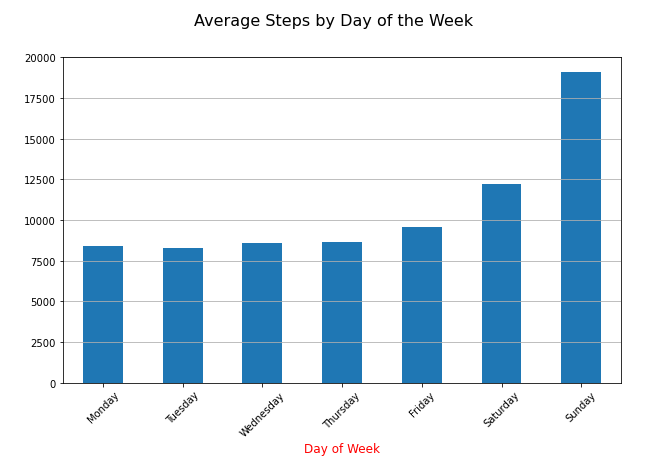
The diagram shows what I already know. I do the most steps on the weekend. But I think it is also interesting that I have overall (2019 - 2021) nearly 8000 steps per day. And when I look into 2021, only I have now almost 10,000 steps, even though I am still in my home office since COVID-19 started. Next, I created an overview of my monthly steps. In the monthly chart, we see an increase during the lockdown in Germany, where you could go out for a walk or run.
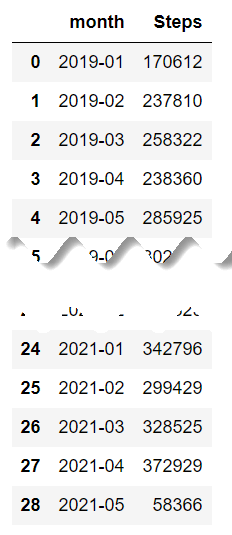
df_steps['value'] = pd.to_numeric(df_steps['value']) total_steps_by_month = df_steps.groupby(['month'])['value'].sum().reset_index(name='Steps') total_steps_by_month
The total_steps_by_month now has all steps of each month summed up, and this is how it looks like:
After looking into the data, I now want to display it as a chart.
dataset = total_steps_by_month chart_title = 'Number of Steps per month' n_groups = len(dataset) index = np.arange(n_groups) ax = dataset.plot(kind='line', figsize=[12, 5], linewidth=4, alpha=1, marker='o', color='#6684c1', markeredgecolor='#6684c1', markerfacecolor='w', markersize=8, markeredgewidth=2) ax.yaxis.grid(True) ax.xaxis.grid(True) ax.set_xticks(index) ax.set_ylabel('Step Count') plt.xticks(index, dataset.month, rotation=90) ax.set_title(chart_title) plt.show()
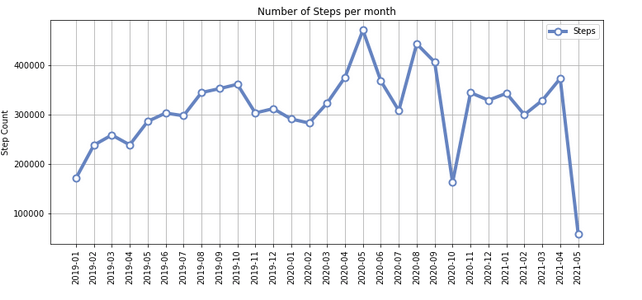
The last chart is an overview of my steps per year, which I already knew from the iPhone app Stepz.
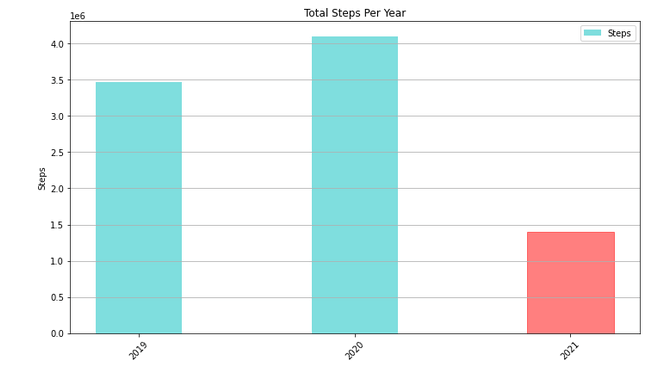
As I now have my data, I could also save it as a CSV file for later use and analyze the hours when I made my steps. It is interesting what you can do with all of this data.
Conclusion
So that's it. I think it is only the iceberg tip of what you can do with Apple Health data. The next steps are to look into the heart rate and how it developed with my running exercises during the two years and the visualization of GPS data. Maybe someone can provide me with a few tips, so I can improve my Python skills. Is there any good video course or book I should read? Leave a comment below.
author.

Hi,
I am Tobias, I write this blog since 2014, you can find me on Twitter, LinkedIn, Facebook and YouTube. I work as a Senior Business Warehouse Consultant. In 2016, I wrote the first edition of Analysis Office - The Comprehensive Guide. If you want, you can leave me a PayPal coffee donation. You can also contact me directly if you want.
Subscribe
- In my newsletter you get informed about new topics
- You learn how to use Analysis Office
- You get tips and tricks about SAP BI topics
- You get the first 3 chapters of my ebook Analysis Office - The Comprehensive Guide for free
You want to know SAP Analysis Office in a perfect detail?
You want to know how to build an Excel Dashboard with your Query in Analysis Office?
You want to know how functions in SAP Analysis Office works?
Then you have to take a look into Analysis Office - The Comprehensive Guide. Either as a video course or as a ebook.
Write a comment
Aaron Benner (Tuesday, 12 April 2022 23:54)
Great blog and good way to branch over to some python stuff.
Totally agreed about AO not getting any new features. But just when we thought they were done, in SP9 they released "Repeat Headers" which allows you to easily put AO into a pivot table or other automation for Power BI etc.
Tobias (Wednesday, 13 April 2022 10:05)
Hi,
you are right, the repeat headers feature is the biggest change in over a year ;)